チュートリアル: AENET 学習パイプライン
本チュートリアルでは、N2 二量体を例に、第一原理計算(Quantum ESPRESSO)から 教師データを作成し、AENET で機械学習ポテンシャルを構築する一連の手順を説明します。
サンプルファイルは sample/aenet_training/ にあります。
ワークフロー概要
1. 構造生成 (relax/)
└→ ランダムなN2二量体構造を生成
└→ QE でエネルギー・力の計算(SCF)
2. 教師データ作成 (relax/)
└→ QE 出力からエネルギー・力を抽出
└→ XSF 形式の教師データを生成
3. フィンガープリント生成 (generate/)
└→ AENET generate.x で原子記述子を計算
4. ニューラルネットワーク学習 (train/)
└→ AENET train.x でポテンシャルを学習
5. 予測・検証 (predict/)
└→ AENET predict.x でテスト構造のエネルギーを予測
└→ QE 計算との比較
Step 1: 構造生成
sample/aenet_training/relax/ ディレクトリで作業します。
structure_make.py は、N-N 結合距離を 0.5〜2.0 Å の範囲でランダムに生成し、
Quantum ESPRESSO の入力ファイルを作成します。
注釈
各ディレクトリに疑似ポテンシャルファイル(N.pbe-n-kjpaw_psl.1.0.0.UPF)が
必要です。run_all.sh を使用する場合は自動的にダウンロードされます。
手動で実行する場合は relax/pseudo_Potential/ ディレクトリに配置してください。
import random
structure_list = []
for i in range(20):
structure_list.append(random.uniform(0.5, 2.0))
テンプレートファイル (template.txt) は QE の入力形式で、value_01 が
N-N 結合距離のプレースホルダーです:
&CONTROL
calculation = 'scf'
tprnfor = .true.
pseudo_dir = './'
outdir = './'
/
&SYSTEM
ntyp = 1, nat = 2, ibrav = 0
ecutwfc = 44, ecutrho = 320
occupations = 'smearing'
smearing = 'mp'
degauss = 0.01
/
...
ATOMIC_POSITIONS angstrom
N 0.00 0.00 0.00
N 0.00 0.00 value_01
注釈
calculation='scf'は各構造で単一点計算(構造緩和なし)を行います。 ランダムに生成した様々な N-N 距離でのエネルギーと力を取得するために使用します。tprnfor=.true.は原子に働く力の出力を有効にします。 AENET の学習データ(XSF ファイル)にはエネルギーと力の両方が必要なため、 このオプションを必ず指定してください。
実行:
python3 structure_make.py
これにより directory_0/ 〜 directory_19/ が生成され、それぞれに QE 入力ファイルが配置されます。
各ディレクトリで QE を実行します:
pw.x < n2_dimer.pwi > n2_dimer.pwo
Step 2: 教師データ作成
QE の出力ファイルからエネルギーと原子間力を抽出し、AENET の XSF 形式に変換します。
teach_data_make.py は ASE の ase.io.read() を使用して QE 出力ファイルを読み込み、
エネルギー(eV)、原子座標(Å)、力(eV/Å)を抽出し、XSF 形式で出力します。
cd directory_0
python3 ../teach_data_make.py --input n2_dimer.pwo --output-dir teach_data
出力例(teach_data_1.xsf):
# total energy = -767.51 eV
ATOMS
N 0.00000000 0.00000000 0.00000000 0.00000000 0.00000000 -12.34567890
N 0.00000000 0.00000000 1.04970000 0.00000000 0.00000000 12.34567890
Step 3: フィンガープリント生成
sample/aenet_training/generate/ ディレクトリで作業します。
generate.in で教師データのパスと原子種を指定します:
OUTPUT N2.train
TYPES
1
N 389.83
SETUPS
N N.fingerprint.stp
FILES
20
../relax/directory_0/teach_data/teach_data_1.xsf
../relax/directory_1/teach_data/teach_data_1.xsf
...
各キーワードの意味:
OUTPUT: 出力ファイル名。フィンガープリントデータを格納するバイナリファイル(ここでは
N2.train)TYPES: 原子種の数(次の行)と、各原子種の元素記号・原子量(
N 389.83は窒素、389.83 は原子エネルギーのシフト値 [eV])SETUPS: 各原子種に対応するフィンガープリント設定ファイル(
N.fingerprint.stp)FILES: 教師データの XSF ファイル数(次の行)と、各ファイルへのパス
N.fingerprint.stp はフィンガープリント(構造記述子)の設定ファイルで、
各原子の局所環境をニューラルネットワークの入力に変換する方法を定義します。
generate.x の入力として必要です。
ファイル形式の詳細は
AENET 公式ドキュメント
を参照してください。
N2 ダイマー用の設定例:
DESCR
Structural fingerprint setup for N-N in linear nitrogen molecule
END DESCR
ATOM N
ENV 1
N
RMIN 0.5
SYMMFUNC type=Behler2011
9
G=2 type2=N eta=0.001 Rs=0.0 Rc=3.0
G=2 type2=N eta=0.01 Rs=0.0 Rc=3.0
G=2 type2=N eta=0.1 Rs=0.0 Rc=3.0
G=4 type2=N type3=N eta=0.001 lambda=-1.0 zeta=4.0 Rc=3.0
G=4 type2=N type3=N eta=0.001 lambda=1.0 zeta=4.0 Rc=3.0
G=4 type2=N type3=N eta=0.01 lambda=-1.0 zeta=4.0 Rc=3.0
G=4 type2=N type3=N eta=0.01 lambda=1.0 zeta=4.0 Rc=3.0
G=4 type2=N type3=N eta=0.1 lambda=-1.0 zeta=4.0 Rc=3.0
G=4 type2=N type3=N eta=0.1 lambda=1.0 zeta=4.0 Rc=3.0
各キーワードの意味:
ATOM: フィンガープリントを計算する中心原子の元素(ここでは N)
ENV: 環境に含まれる原子種の数と元素記号。N2 は単元素系なので 1 種(N のみ)
RMIN: 原子間距離の下限(Å)。これより近い構造は除外される
SYMMFUNC type=Behler2011: Behler の対称関数 [J. Behler, J. Chem. Phys. 134, 074106 (2011)] を使用
実行:
generate.x generate.in > generate.out
出力:
N2.train: 学習用バイナリデータセット
Step 4: ニューラルネットワーク学習
sample/aenet_training/train/ ディレクトリで作業します。
train.in で学習パラメータを設定します:
TRAININGSET N2.train
TESTPERCENT 10
ITERATIONS 3000
TIMING
bfgs
NETWORKS
# atom network hidden
# types file-name layers nodes:activation
N N.5t-5t.ann 2 10:tanh 10:tanh
各キーワードの意味:
TRAININGSET:
generate.xで生成したフィンガープリントデータファイル(ここではN2.train)TESTPERCENT: 教師データのうちテストに使用する割合 [%](ここでは 10%)
ITERATIONS: 重み最適化の反復回数(ここでは 3000 回)
TIMING: 各反復の実行時間を出力する
bfgs: 重み最適化手法の選択。以下の 3 つから選択可能:
steepest_descent: オンライン最急降下法bfgs: BFGS 準ニュートン法(推奨)levenberg_marquardt: Levenberg-Marquardt 法
NETWORKS: ニューラルネットワークの構成。各行に以下を指定:
原子種の元素記号(
N)出力する ANN ポテンシャルファイル名(
N.5t-5t.ann)隠れ層の数(
2)各隠れ層のノード数と活性化関数(
10:tanh 10:tanh)
実行:
train.x train.in > train.out
学習結果の例(train.out より):
Number of training structures : 18
Number of testing structures : 2
Total number of weights : 221
Atomic energy shift : -747.530391 eV
出力:
N.5t-5t.ann: 学習済み ANN ポテンシャルファイル
Step 5: 予測・検証
sample/aenet_training/predict/ ディレクトリで作業します。
まず generate_test_xsf.py でテスト用の XSF ファイルを生成します。
N-N 距離 0.00〜2.00 Å を 0.01 Å 刻みで 201 構造作成します:
python3 generate_test_xsf.py
これにより predict_data_set_test/ ディレクトリにテスト用 XSF ファイルが生成されます。
次に、predict.in で予測の設定を行います:
TYPES
1
N
NETWORKS
N N.5t-5t.ann
FORCES
FILES
201
../predict_data_set_test/test_0.00.xsf
../predict_data_set_test/test_0.01.xsf
...
各キーワードの意味:
TYPES: 原子種の数(次の行)と各原子種の元素記号
NETWORKS: 各原子種に対応する学習済み ANN ポテンシャルファイル(
N.5t-5t.ann)FORCES: 力の予測も行う(省略可)
FILES: 予測対象の XSF ファイル数(次の行)と各ファイルへのパス
学習済みポテンシャルによるエネルギー予測を実行します:
predict.x predict.in > predict.out
結果の可視化
plot_distance_energy.py を使用して、ANN ポテンシャルによる予測エネルギーと QE の
第一原理計算結果を比較するプロットを作成できます:
python3 plot_distance_energy.py \
--predict-out predict.out \
--train-out ../train/train.out \
--qe-dir ../relax \
--n-structures 20 \
--output distance_energy_plot.png
このスクリプトは以下の 3 つのデータセットをプロットします:
ANN 予測 (青):
predict.outからの原子間距離 vs エネルギーQE 教師データ (赤): SCF 計算の XSF ファイルからの結果
QE テストデータ (緑):
train.outのテストセットに含まれるデータ点
全体表示(distance_energy_plot.png)に加え、ポテンシャルの底部を拡大した
ズームインプロット(distance_energy_plot_zoom.png、y 軸: -770〜-760 eV)
も自動的に生成されます。
計算結果
以下のグラフは、ANN ポテンシャルによる予測エネルギーと QE の第一原理計算結果を 比較したもの(ポテンシャル底部のズームイン)です。
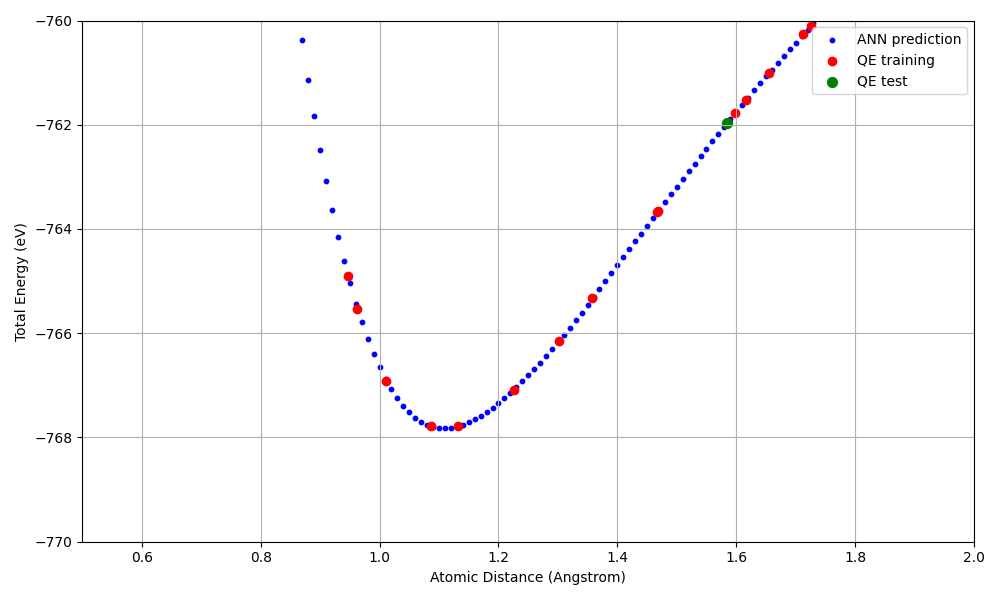
N2 二量体のエネルギー-距離曲線(ズームイン)。青: ANN 予測、赤: QE 教師データ、緑: QE テストデータ。
主な結果:
平衡 N-N 距離(約 1.1 Å)付近でエネルギーが最小(約 -768 eV)となる Morse 型のポテンシャル曲線が再現されている
教師データ(20 点)の範囲内で ANN ポテンシャルが QE の結果をよく再現